Kumpel 2.0 — Portfolio AI Assistant
LiveA RAG chatbot backed by a Hindsight graph database, built in a day to serve as a living application package — with Claude Code hooks, Skills, and an MCP server keeping the knowledge base current as site content evolves. It is aware of the n8n job description and hiring criteria and prompts users with follow up questions they might find interesting to guide them through the experience. Give it a try, it's in the right-bottom corner.
The Backstory
The original Kumpel.ai was a 2023 capstone project for Dan Shipper's AI course at Every.to — a "chat with your Notion" product I built months before Notion shipped their own Q&A feature. Django backend, OpenAI embeddings, vector search, OAuth integration. It validated the core insight: people want to talk to their documents, not search through them. That Notion eventually built the same thing wasn't a failure — it was validation.
Kumpel 2.0 takes that same RAG pattern and rebuilds it from scratch as a portfolio AI assistant, purpose-built for my n8n application. Different stack, different purpose, same instinct.
The Problem
A static portfolio page can't answer questions. It can't connect dots across 20+ projects, explain architectural decisions, or highlight how specific work maps to a job posting. I needed something that could — and I needed it fast, because the n8n AI Product Builder role was open.
My Role
Solo builder. Designed and built the entire system in one day: FastAPI backend, RAG/Graph pipeline, chat widget, streaming infrastructure, and deployment. The content ingestion and knowledge base maintenance use Claude Code hooks, Skills, and a Hindsight MCP server working in tandem.
The Approach
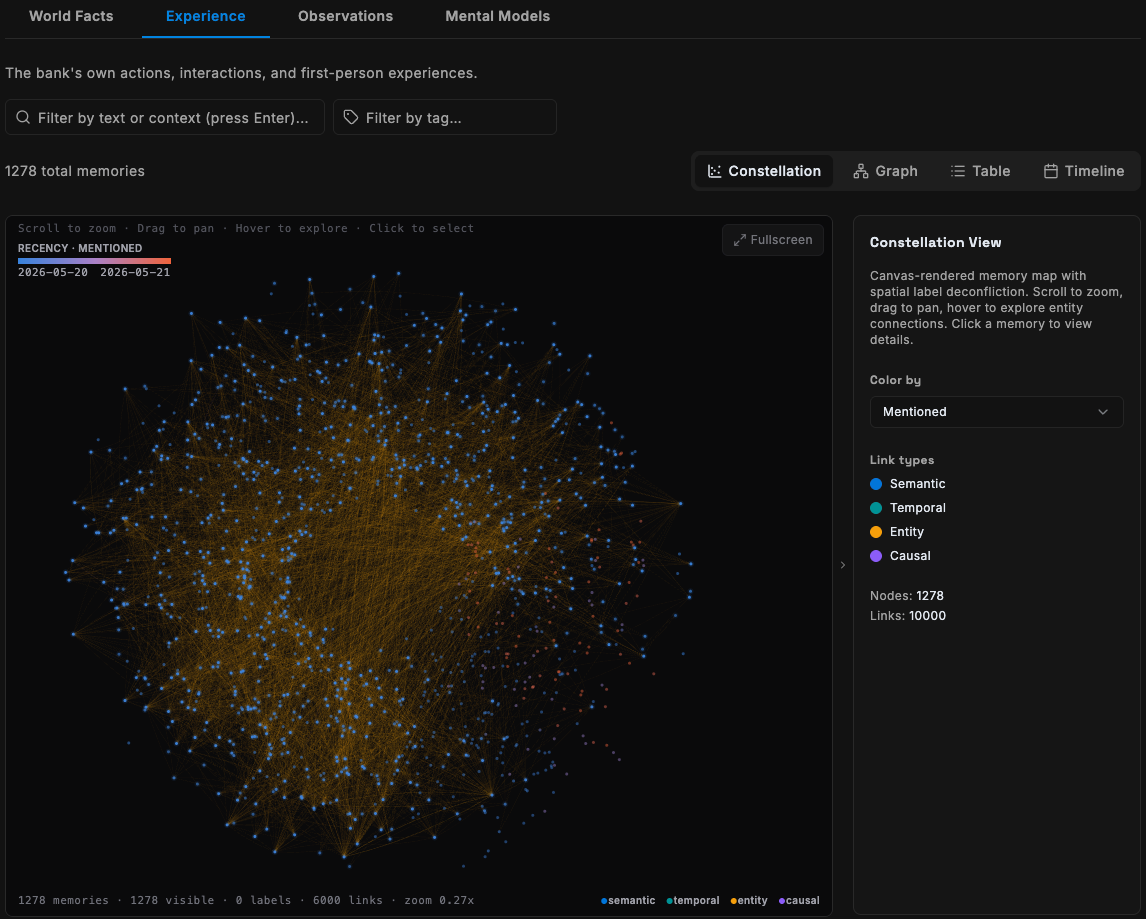
Graph memory instead of flat vectors. The original Kumpel used a traditional vector database. Kumpel 2.0 uses Hindsight, a graph memory service that understands relationships between entities — projects, technologies, roles, timelines. When someone asks "how do Dan's projects connect to each other?", the graph traversal finds connections that pure vector similarity would miss.
Streaming with word-boundary buffering. SSE streaming sends responses token-by-token, but naive streaming causes visual artifacts — words split mid-syllable ("M BO", "n 8n"). The backend accumulates an 80-character buffer and only flushes on word boundaries (spaces, newlines), eliminating mid-word splits without adding perceptible latency.
Programmatic citations, not LLM-generated. Source links come from Hindsight metadata, not from the LLM's output. The system appends citations after the response based on which documents were retrieved — so citations are always accurate and never hallucinated.
n8n-aware system prompt. The system prompt includes the full n8n job posting and understands both workstreams (AI Building/Super Agent and AI Trust). It frames answers to highlight how Dan's work maps to what n8n needs — naturally, not forced. Every response ends with contextual follow-up questions rendered as clickable chips.
What I Built
- FastAPI backend — serves both the static Astro portfolio and the chat API from a single Docker container
- Hindsight RAG pipeline — 326 chunks from 32 scrubbed content files ingested into a graph memory bank, with entity and relationship extraction
- SSE streaming chat — word-boundary buffered streaming with proper multi-line SSE parsing on the client
- Vanilla JS chat widget — three size modes (compact/expanded/maximized), model selector (Claude Sonnet or Gemma 27B), follow-up question chips, session persistence, mobile-optimized with safe-area handling
- Multi-provider LLM layer — configurable between OpenRouter (Claude), GreenPT (Gemma 27B), and local LLMs via Tailscale. Switch providers per-request.
- Knowledge base maintenance — Claude Code hooks, Skills, and Hindsight MCP server work in tandem to keep the graph database current as site content evolves
- Rate limiting — IP-based sliding window (30 requests/hour) with friendly message, plus 10-turn session reset to prevent context overload
- Conversation memory — in-memory per-session history (max 10 turns) for contextual follow-ups
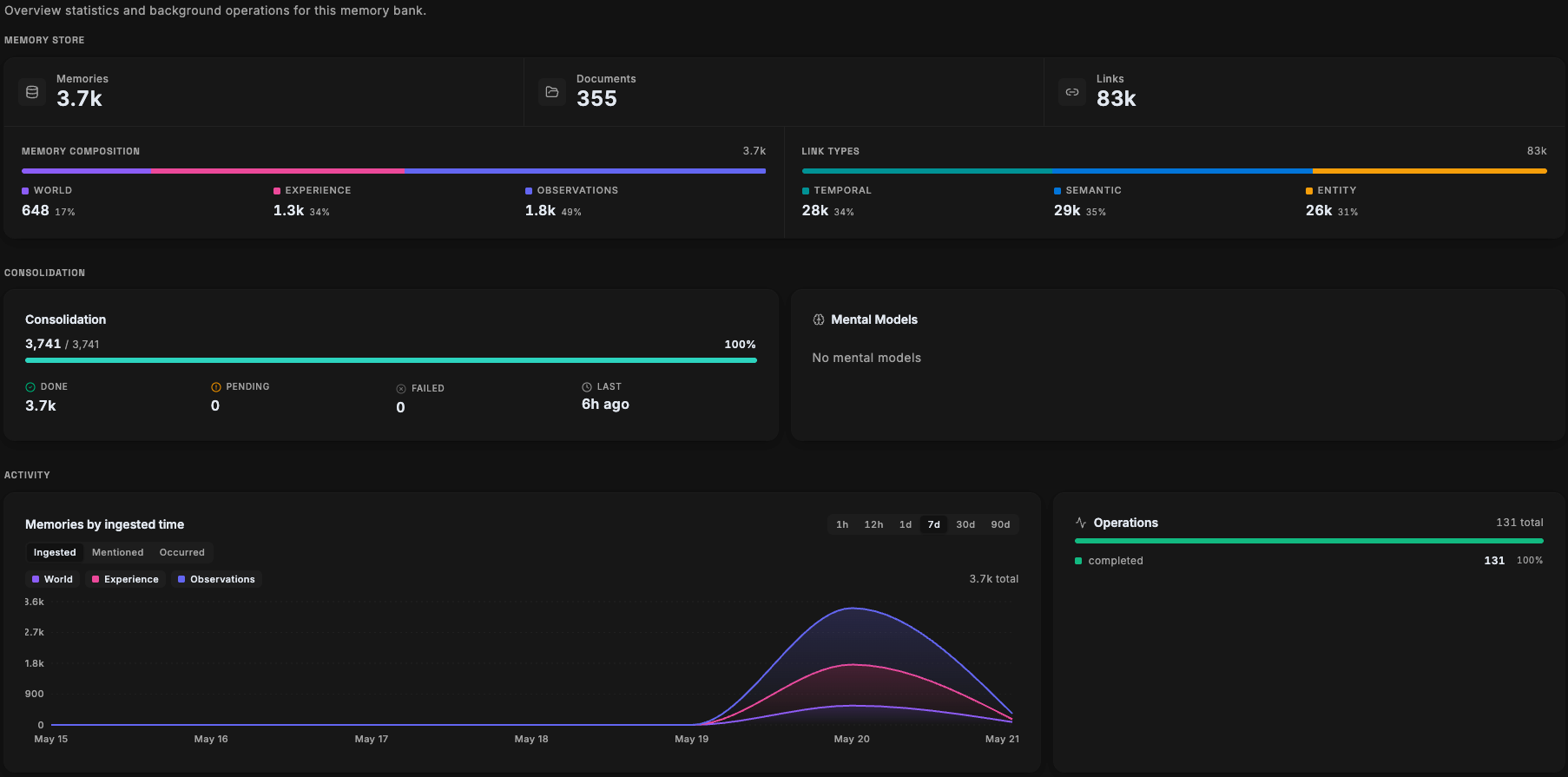
Hindsight Stats: 3.7k memories, 83k links
355 documents fully consolidated into 3,741 memories across world facts, experiences, and observations — with 83,000 semantic, temporal, and entity links.
The Result
A production chatbot that knows over a dozen projects intimately and frames them for the n8n hiring audience. It handles questions about architecture, cross-project patterns, career background, and the builder track positioning — with accurate citations and contextual follow-ups. The dual-provider setup means visitors can choose between Claude Sonnet (quality) and Gemma 27B (open-source, carbon-neutral hosting).
The meta-point: this chatbot IS the application. It demonstrates RAG architecture, streaming infrastructure, multi-provider LLM integration, graph memory, prompt engineering, and production deployment — all the patterns relevant to n8n's AI Product Builder role. And it was built in a day.
Tech Stack
- Backend: FastAPI, Python 3.12
- Memory: Hindsight (graph memory service with RAG)
- LLM: OpenRouter (Claude Sonnet), GreenPT (Gemma 27B), local LLM via Tailscale
- Frontend: Astro (static site), vanilla JS widget
- Streaming: SSE with word-boundary buffering
- Deployment: Docker (multi-stage build), Appliku
- Maintenance: Claude Code Hooks + Skills, Hindsight MCP server